

Sometime in the last twelve months, the web quietly flipped. For the first time in its history, more requests now come from machines than from people. If you run your own server and pull in sensitive third-party data, that single fact rewrites your threat model. The visitors hammering your endpoints are no longer mostly humans with the occasional crawler sprinkled in. They are mostly software, and a meaningful slice of that software is actively hostile.
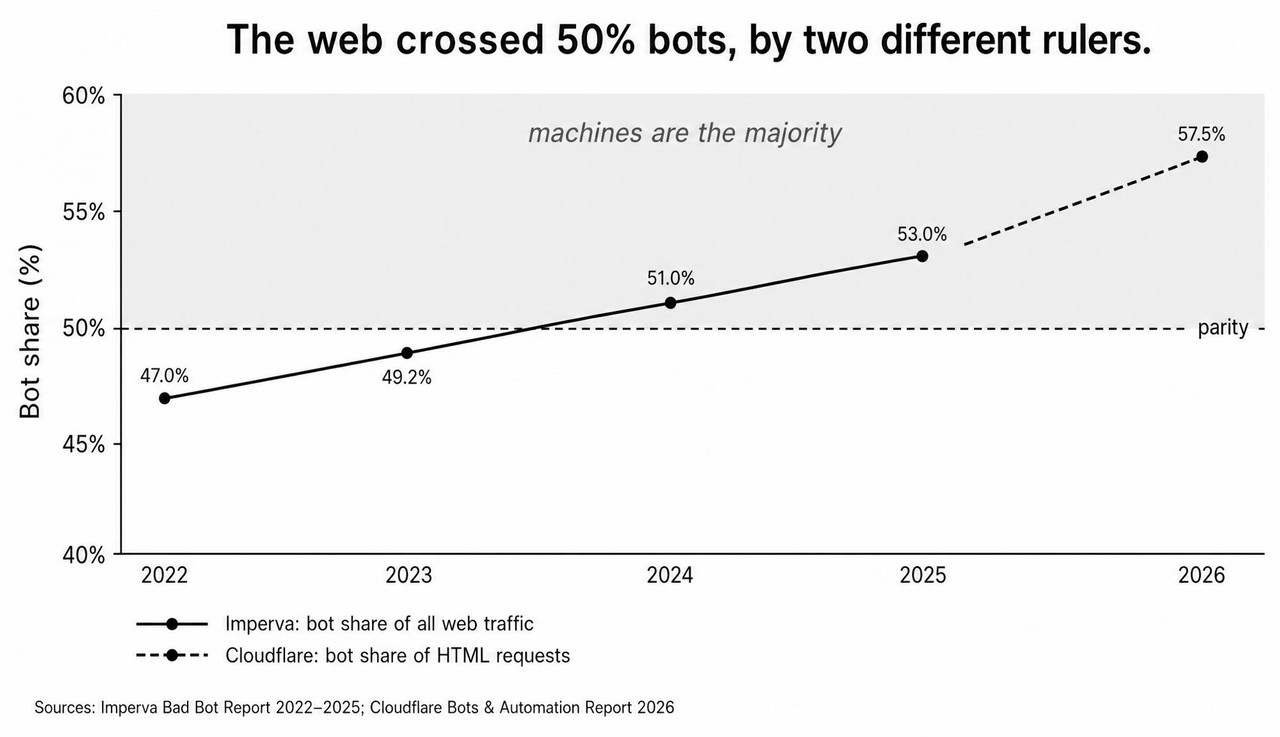
The numbers are not ambiguous. Imperva’s 2026 Bad Bot Report, drawn from full-year 2025 data across its global network, found that automated traffic reached 53% of all web traffic, up from 51% the year before, while human activity slipped to 47% and kept falling. Cloudflare, measuring HTML requests across roughly one-fifth of the web, put the bot share even higher at about 57.5%. The two studies count different baskets, so the figures should not be averaged, but they point the same way: humans are the minority shareholders now.
For the CyberPanel reader running a self-hosted pipeline, the headline is not the percentage. It is what the percentage does to three things you cannot avoid: how you architect ingestion, how you harden endpoints, and how you prove a request came from a human at all.
The crossover, in one picture
Two independent rulers, one direction of travel. The chart below shows the human share of web traffic falling below the bot share, with the Imperva and Cloudflare measurements plotted side by side so the reader can see they disagree on magnitude but agree on the verdict.
The ingestion side: keeping a pipeline alive in an arms race
Start with the side most self-hosters underestimate: getting clean data in. If you build a local pipeline that pulls from exchanges, help centers, and other public endpoints, you are now operating inside a fight you did not start. The same anti-bot defenses raised to stop malicious scrapers also catch your perfectly legitimate fetcher, because from the server’s perspective your automated request and an attacker’s look identical.
Few people feel this more acutely than operators of self-hosted crypto-tax pipelines, where the inputs are scattered across dozens of exchanges that each format, timestamp, and rate-limit differently. CoinLedger‘s David Kemmerer has been on record about exactly this failure mode. In CyberPanel’s earlier walkthrough of a self-hosted n8n crypto-tax pipeline, Kemmerer described the most common failure for self-hosting investors as data drift: missing or inaccurate data and mismatched timestamps across exchanges that quietly corrupt the ledger. The same piece noted that pulling data from exchanges, help centers, and other public endpoints has become extremely fragile and complex precisely because anti-bot defenses are intensifying.
Reframed for the bot-majority web, his point sharpens. “When the endpoints you depend on are busy fighting bots, your own honest automation becomes collateral damage,” is the operator’s reality: a defensive rate limit tuned for an attack wave will throttle your nightly sync just the same. Kemmerer’s prescription for the ingestion side is unglamorous and correct. Treat every external feed as untrusted and unstable. Reconcile across sources rather than believing any single one. Stamp everything in UTC at the moment of capture so a clock skew between exchanges cannot silently rewrite a cost basis. And assume the endpoint you scraped cleanly last night may greet you with a challenge page tonight.
There is a second, darker half to his vantage point. A self-hosted financial pipeline does not just consume from a hostile web; it also sits on the web holding high-value data. A box that contains years of crypto transaction history is exactly the target an agentic attacker wants, and the tooling to come after it is the same tooling everyone now has.
The attacker uses your stack
This is the uncomfortable symmetry of 2026: the agentic tools that extract data are the agentic tools that attack accounts. HUMAN Security’s 2026 State of AI Traffic report, built on more than a quadrillion analyzed interactions, captured how thin the line has become. Across everything its platform observed, only one half of one percent separated the rate of benign automation from the rate of malicious automation. Put differently, the well-behaved bot and the attacker are now nearly indistinguishable by volume and behavior alike.
The same body of research found account-takeover activity climbing sharply, with credential stuffing and post-login session abuse riding on automation that mimics human pacing. Imperva’s report adds the sector detail that should make any operator of financial data sit up: financial services absorbed 46% of account-takeover incidents and 24% of all bot attacks, and 27% of bot attacks now hit APIs directly, bypassing the human-facing interface entirely. If your ingestion pipeline exposes an API, that API is the front door attackers prefer.
Same tool, two jobs
It helps to lay the symmetry out plainly. Every capability you rely on to ingest data has a mirror-image use as an attack technique. The table below maps the overlap so you can see why defenses that target the technique, not the intent, are the only ones that hold up.
| Capability | Your legitimate use (ingestion) | Attacker’s use against you |
|---|---|---|
| Headless browser | Render a JavaScript-heavy exchange page to read balances | Defeat login forms and solve interactive challenges at scale |
| Rotating proxies | Spread polite requests to respect per-IP rate limits | Distribute credential stuffing so no single IP looks abusive |
| Human-like pacing | Avoid tripping a feed’s anti-bot throttle | Slip account-takeover attempts past behavioral detection |
| API access | Pull structured data without scraping HTML | Hit authentication and payment endpoints directly |
| LLM extraction | Parse messy help-center text into structured records | Harvest your published content and student writing for training |
The content side: defending human work when you cannot assume humans
The ingestion problem is about data you pull. The mirror problem is about data you hold and the words humans wrote. Nowhere is that sharper than in education, where the asset is student writing and the legal stakes are personal.
Jay Speakman, CTO of the academic-writing platform CustomWritings, frames the other half of the spine. His concern is not keeping a feed alive; it is protecting human-authored content and student records on a web where you can no longer assume the reader is a person. Two pressures collide. The first is training scrapers that ignore robots.txt and harvest original writing as raw material, turning a student’s essay into someone else’s model weights without consent or attribution. The second is privacy law. Student writing carries FERPA-grade obligations about where it is processed and who can touch it, which is a large part of why the sector is moving toward local control of its AI infrastructure rather than shipping every document to a third-party API.
Speakman’s deeper observation is technical, and it ties the whole article together. The problem of telling a human-written essay from machine-generated text is, at bottom, the same problem as telling a human visitor from a bot. Both rest on the same statistical tells: perplexity, rhythm, the small inconsistencies of genuine human behavior versus the suspiciously smooth output of a model. “Is this text actually human?” and “is this request actually human?” are two faces of one fingerprinting question, and an operator who can answer one is most of the way to answering the other.
For self-hosters that is genuinely good news. The behavioral signals that flag a scraping bot, the absence of natural mouse movement, impossibly consistent timing, requests that never load a stylesheet, are cousins of the signals that flag machine-written text. Investing in one detection layer pays down both risks at once.
Which leads to the genuinely absurd place we have arrived. The classic test for proving you are human was asking you to identify the traffic lights. In 2026 the bots solve those faster than you do, so a growing number of sites have given up on puzzles and started watching how clumsily you move the mouse. The robots got so good at proving they were human that the only reliable proof of humanity left is being visibly bad at using a computer. Somewhere a CAPTCHA is failing an honest accountant for clicking the crosswalk too efficiently, and waving through a botnet that learned to fumble on purpose.

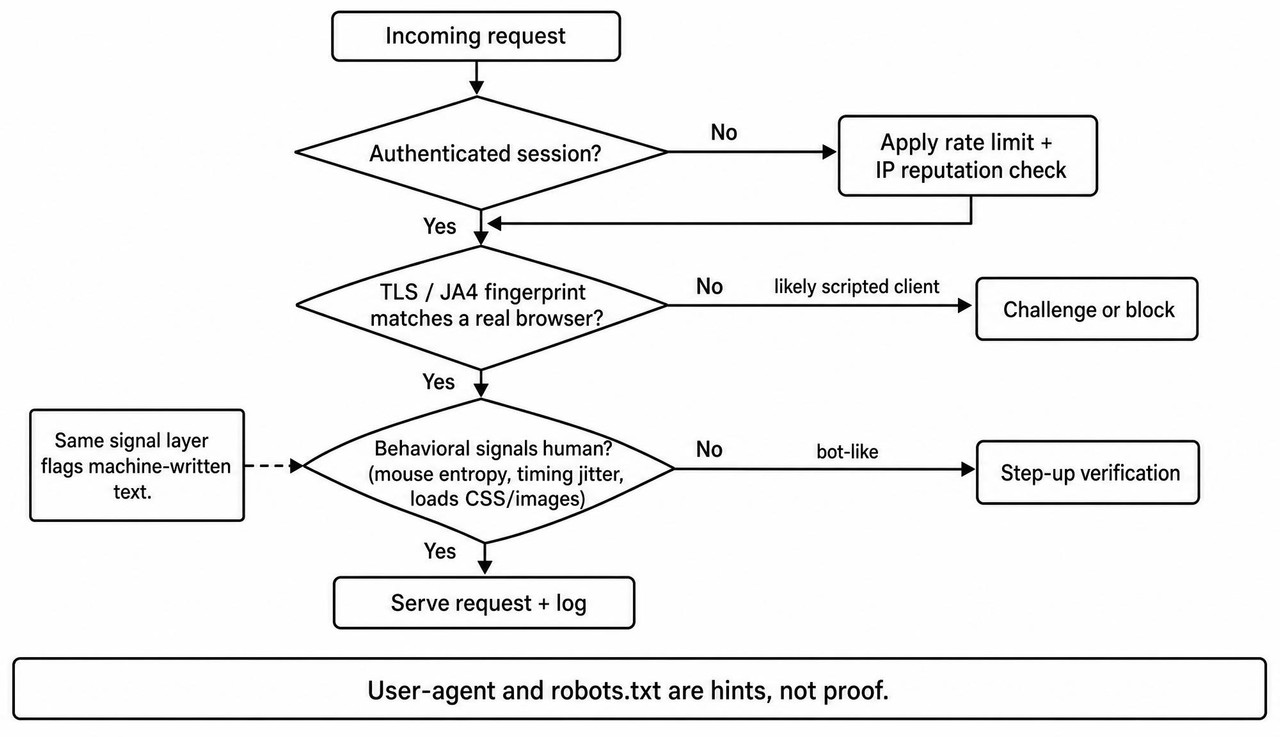
Where to spend your defensive budget
Because user-agent strings can be spoofed and robots.txt is voluntary, the durable defenses live deeper in the stack. The decision flow below shows how to triage an incoming request without ever trusting what it claims to be.
Watch: how machines defeat the human test
For a concrete look at how modern automation slips past the very defenses described above, the talk below from a developer who builds these systems walks through how scrapers mimic human behavior to bypass sophisticated anti-bot detection. It makes the article’s core point tangible: the line between a human request and a machine request is now something you have to actively measure, not assume.
The self-hoster’s playbook for a bot-majority web
Pulling both sides together, here is the architecture that survives contact with a web where machines move more traffic than people.
- Treat every external feed as untrusted and unstable. Reconcile across multiple sources, stamp every record in UTC at capture, and alert on data drift rather than discovering it at filing time, the failure mode Kemmerer flags.
- Defend the technique, not the label. User-agent and robots.txt are courtesy, not security. Lean on TLS and JA4 fingerprinting, IP reputation, and rate limiting as your first hard layer.
- Make the API the fortress, not the afterthought. With 27% of bot attacks aimed straight at APIs, every ingestion endpoint needs authentication, strict rate limits, and anomaly detection in its own right.
- Invest once in behavioral detection, collect twice. The signals that catch a scraping bot are cousins of the signals that catch machine-written text, Speakman’s point. One layer, two protections.
- Keep sensitive processing local. For FERPA-grade student data or high-value financial history, local control over AI infrastructure is fast moving from nice-to-have to baseline.
- Assume your honest automation looks malicious. Build retry, backoff, and challenge-handling into your fetchers, because the defenses guarding your sources cannot tell you apart from an attacker.
The bottom line
The bot-majority web is not a forecast to brace for; it is the operating environment you are already in. The reassuring part is that the two halves of the problem share a spine. Whether you are keeping a fragile crypto-tax pipeline fed or shielding a student’s essay from a training scraper, the underlying question is the same: can you tell a human from a machine when the machine is trying hard to look human? Build for that question, harden the technique rather than the label, and keep the high-value data close. Your server is outnumbered. It does not have to be outmatched.

