

Open your marketing analytics and your raw server logs side by side, point them at the same website, the same week, and the same set of URLs, and they will tell you two completely different stories about who showed up and why. One dashboard shows a tidy stream of humans, a handful of familiar traffic sources, and the occasional unexplained jump in visits filed under direct. The other shows a relentless tide of requests at all hours, sharp bursts at three in the morning, and a guest list full of names like GPTBot, ClaudeBot, and PerplexityBot. Same site. Same period. Two realities that flatly refuse to agree.
This is not a tracking bug, and it is not something a clever filter will quietly fix. It is the predictable consequence of one technical fact about how the web now works, and in 2026 that fact crossed a line that should change how every site owner reads their numbers.
The one fact that split the web in two
The fact is this: machines are now the majority of web traffic, and machines do not run JavaScript.
Start with the majority part. On 3 June 2026, Cloudflare CEO Matthew Prince shared Radar data showing that automated requests had reached 57.5 percent of HTML traffic to web content, against 42.5 percent from humans. It was the first time in the history of the internet that machines held the majority, and it arrived ahead of Cloudflare's own forecast. The composition matters too. Inside that automated share sit traditional search crawlers, uptime monitors and feed readers, the fast-growing wave of AI training and answer crawlers, and a large and still-climbing population of bad bots.
Now the JavaScript part, which is where the two dashboards quietly part ways. Tools like Google Analytics 4 measure a visit by running a snippet of JavaScript inside the visitor's browser. When a real person loads your page, that script fires, sets cookies, and records a session. AI crawlers do not behave like browsers. They send an HTTP request, receive the raw HTML, parse the text, and move on. They never execute your tracking script, so it never fires. The result is brutally simple: the fastest-growing segment of your traffic is structurally invisible to the dashboard most marketers treat as the source of truth. Your server, by contrast, writes down every single request the instant it arrives, JavaScript or not.
That one asymmetry is why a website is no longer a single place with a single set of numbers. It is two overlapping realities: an infrastructure view that captures everything that hits the wire, and a marketing view that captures only the slice of everything that agrees to run your code. They were always slightly different. In a machine-majority web they are now telling opposite stories. And the difference is not just academic, because the same blindness that hides crawlers from your analytics also hides the single biggest emerging question in search visibility: which AI engines are reading your content well enough to cite it. That answer engine optimization opportunity is sitting in your logs, and only in your logs.
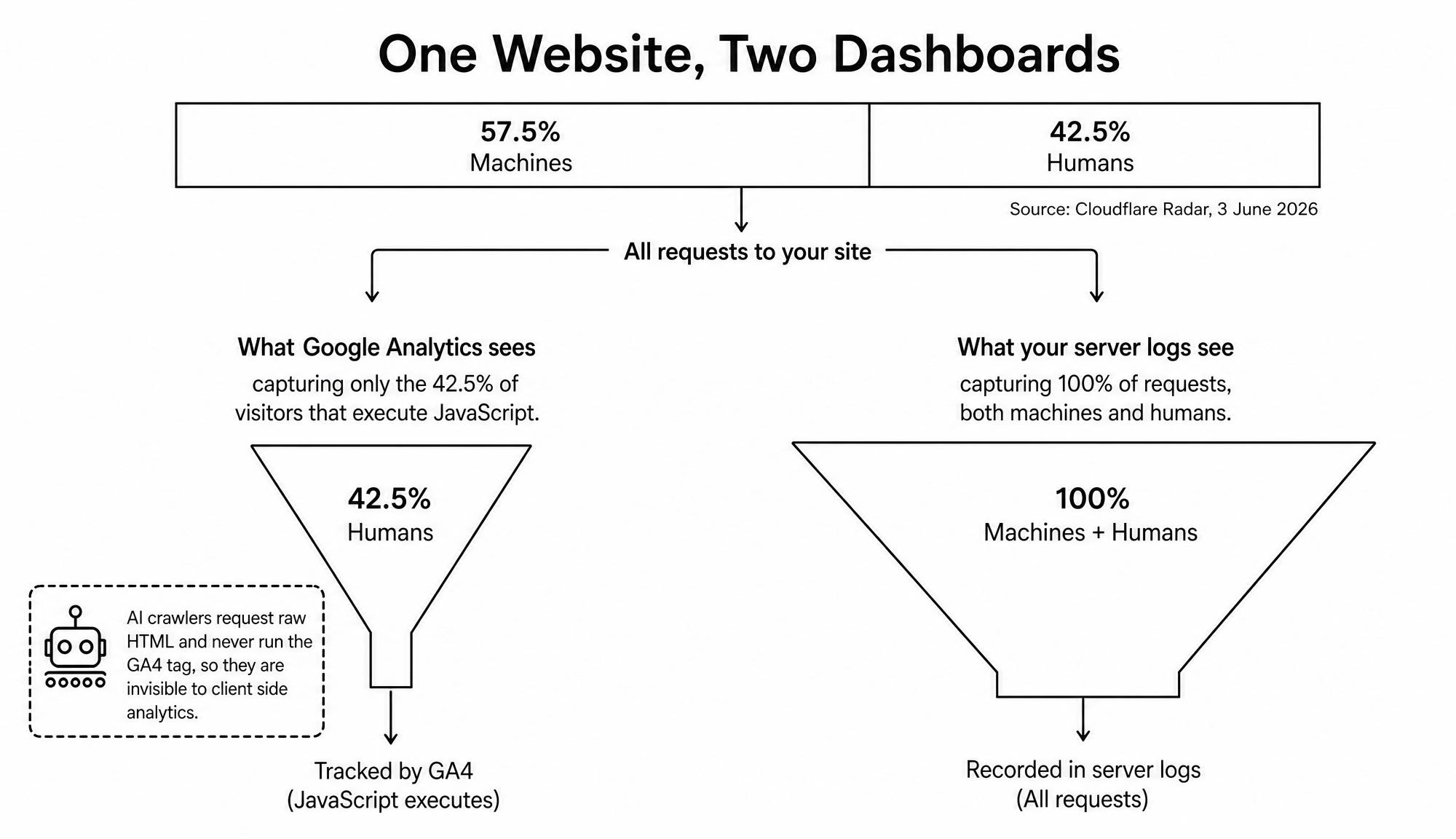
The infrastructure dashboard sees the whole iceberg
If the marketing dashboard shows the tip, the server logs show the iceberg, and the part below the waterline is where both the load and the danger live.
AI crawlers do not sip politely. They arrive in bursts. Log studies through early 2026 have caught individual crawlers firing well over a hundred requests a minute inside a three-minute window, then going quiet for hours. On a generously provisioned site this is background noise. On a shared host or an under-provisioned origin it shows up as latency spikes, a wall of 429 too-many-requests responses, and, when capacity finally gives out, a storm of 5xx errors that drag real customers down alongside the bots. None of that reaches a JavaScript analytics report, because by definition the requests that failed never ran your script.
The security picture is sharper still. According to the 2026 Imperva Bad Bot Report, produced with Thales, automated traffic reached 53 percent of all web traffic in 2025, of which roughly 40 percent came from bad bots built to scrape content, commit fraud, take over accounts, or overwhelm servers. Imperva reported blocking 17.2 trillion bot requests across the year and found that AI-enabled attacks had surged more than twelve-fold. Those are not numbers a marketing tool was ever built to surface. They live in logs, edge events, and your web application firewall, which is precisely why the infrastructure team and the growth team have started to disagree about reality.
“The hard part is not seeing that traffic is up, it is telling signal from noise,” says Andrew Libby, CTO and Co-Founder atStatusGator, the cloud monitoring platform. “A verified crawler indexing your content, an agent fetching a live answer for one user, and a malicious scraper wearing a Chrome user-agent can all look like the same request spike at first glance. If your logs do not separate AI crawlers from humans and from bad actors, you are flying blind on three things at once: how your infrastructure is holding up, whether your content is even being seen by the systems that now decide visibility, and who is quietly abusing you. The work starts at the edge, where you can verify identity instead of trusting a label.”
The marketing dashboard is quietly lying to you
The marketing view has the opposite problem. It is not overwhelmed. It is misled.
Begin with the mystery spikes. When an AI assistant or a poorly behaved bot does manage to trip a pageview, or when a human arrives from an AI answer that strips the referrer, the visit lands in the bucket every analyst dreads: direct. The scale of that missing attribution is large. Analyses of Cloudflare data have found that the great majority of AI-driven referrals never show up correctly in GA4 at all, which means reported AI contribution can be undercounted several times over. Your source reports drift out of focus, channels that earned the visit get no credit, and the direct bucket swells with traffic that actually came from somewhere very specific.
Underneath the attribution mess sits a deeper economic shift. AI systems crawl vastly more than they refer. In the week spanning late May into early June 2026, Cloudflare measured Anthropic's crawler at roughly 11,122 pages crawled for every single visitor it sent back, with OpenAI near 857 to 1, against Google's traditional 5 to 1. Most of that crawling exists to train a model or to answer a question in place, not to send you a click. So the old reflex of judging content purely by the traffic it drives now misses most of what your content is actually doing in the world.
There is a budget cost to the confusion as well. Some of the non-human traffic that does slip past filters is fake or low-intent by design, and when it inflates your visitor counts it also distorts the decisions you build on top of them. Bid more on a channel because it looks busy, reward a publisher because its numbers look strong, optimize a landing page for an audience that turns out to be a script, and you are spending real money to please visitors who were never going to convert. Bad data does not just mislead; it quietly reallocates your budget toward ghosts.
Here is the part that should make any growth team sit up. It is like installing a state-of-the-art doorbell camera that only records visitors who knock in iambic pentameter. Technically it works perfectly. It is just that the 57 percent of callers who do not knock in verse walk straight in, photocopy your files, eat everything in the pantry, and leave, while the footage shows an empty porch the whole time. Then the marketing team reviews the empty footage, sees a quiet week, and concludes the neighborhood must be perfectly safe.
For businesses where a visit is supposed to become a real, billable human action, this is not academic. “Our entire model rests on proving that a click became a genuine, high-intent phone call,” says Sergey Galanin, SEO Director atPhonexa, the pay-per-call platform. “When the dashboard is polluted with traffic that has no eyes, no intent, and no phone, every number downstream becomes suspect: cost per lead, source quality, conversion rate. The pivot is to stop asking only what drives clicks and start asking which AI engines cite you, because a citation today is what produces the high-intent call tomorrow. But you cannot court the bots that help you, or block the ones that only cost you, until you can actually see them, and you will not see them in client-side analytics.”

Reconciling the two dashboards
Reconciliation does not mean blending the two views into one comfortable number. It means capturing everything in one place, classifying it honestly, and then making deliberate decisions about each kind of traffic instead of letting a default decide for you.
Capture at the edge or the origin
The only layer that sees every request is your server, CDN, or edge. That is where logging has to happen, recording the user-agent, the IP address, the timing, and the status code for every hit. Client-side tags will keep missing the machines by design, so server-side or edge logging is not an upgrade, it is the floor.
Classify ruthlessly
A user-agent string is a claim, not proof, and bad bots routinely wear a Chrome costume and route through residential proxies. Verify the crawlers that publish their IP ranges using reverse DNS, separate verified AI crawlers from agents fetching live answers and from outright malicious traffic, and alert on the anomalies rather than the raw totals. A sudden two-hundred-percent jump in bot requests to an expensive endpoint is a story; the daily total is not.
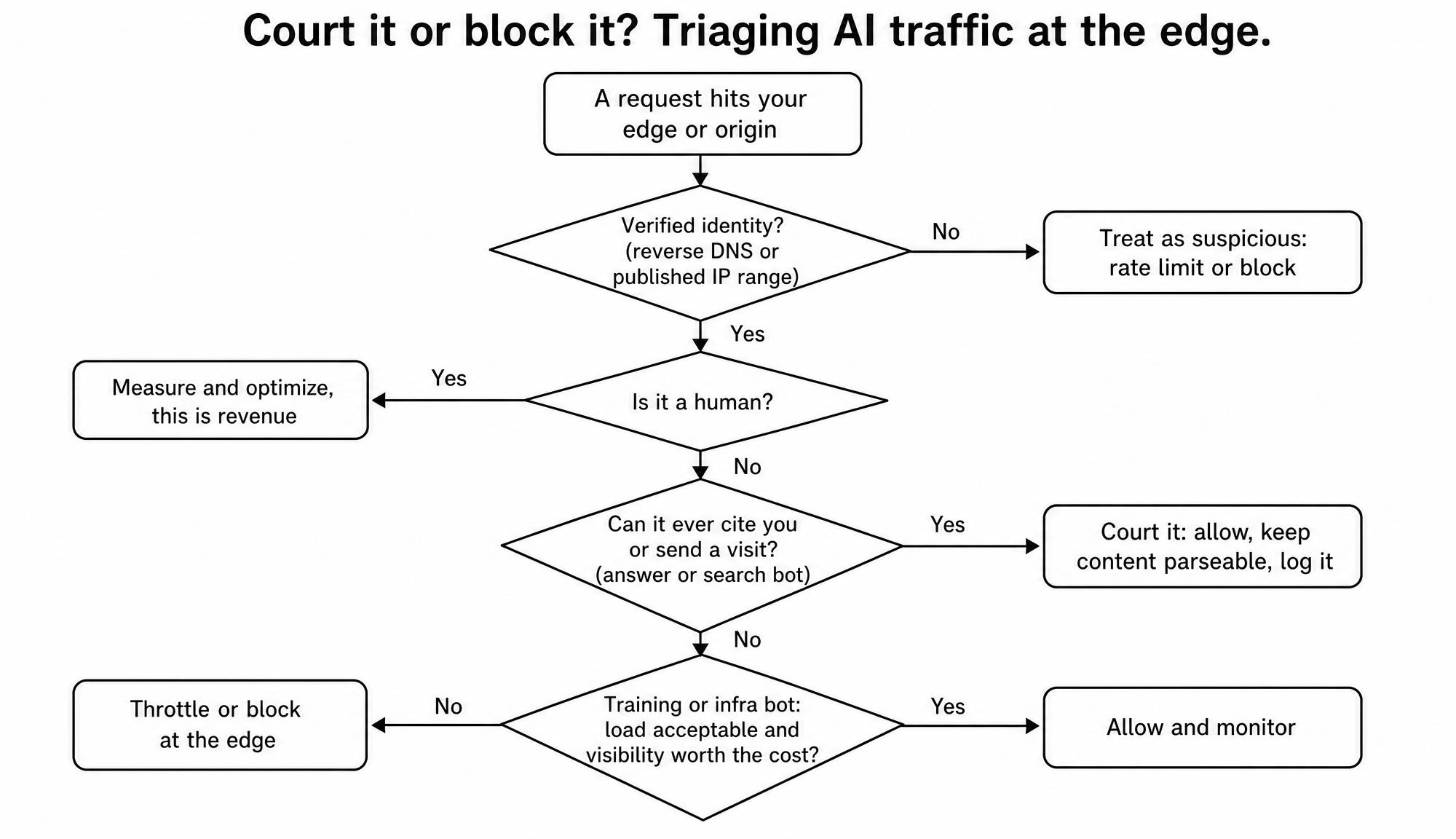
Decide who to court and who to block
Not every bot deserves the same treatment, and the right posture depends entirely on whether the crawler can ever return value to you. The table below is a working triage.
| Traffic type | Examples | Seen in GA4? | What it does to you | Recommended posture |
|---|---|---|---|---|
| Verified human | Browser sessions, real callers | Yes | Revenue, the reason the site exists | Measure and optimize for it |
| AI answer and search bots | OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User | No | Can cite you and refer high-intent visits | Court: allow and keep content parseable |
| AI training crawlers | GPTBot, ClaudeBot, CCBot, Google-Extended | No | Heavy load, little or no referral | Decide case by case: visibility vs cost |
| Benign infrastructure bots | Uptime monitors, feed readers | No | Operational signal, light load | Allow and keep monitoring |
| Malicious bots | Scrapers, credential stuffers, fake-browser bots | Rarely | Fraud, load, polluted analytics | Block and rate-limit at the edge |
Protect both budgets at once
The same classification protects two things that used to belong to two different teams. Clean traffic data protects the marketing budget from being spent against a phantom audience, and edge controls protect uptime and crawl budget from being eaten by bots that will never convert. Treat AI crawler monitoring the way you already treat uptime monitoring: an always-on motion, not a once-a-year audit, with alerts that fire when a single bot's volume spikes overnight or when an important page that used to be crawled suddenly is not.
The point is not to pick a dashboard
The two dashboards were never wrong. They were answering different questions. Your marketing analytics asks which humans chose you and what they did once they arrived. Your server logs ask what actually hit your infrastructure. For most of the web's history those questions had nearly the same answer, so nobody noticed the gap between them. In a machine-majority web they have come apart, and the space between them is exactly where your load problems, your security exposure, your attribution errors, and your future AI visibility all quietly hide.
You do not have to choose one dashboard over the other. You have to read both, reconcile them at the edge, and stop assuming that a quiet porch means nobody came. In 2026, somebody almost always did. They just did not knock in iambic pentameter.

