

People often confuse both types of computing when comparing Fog computing vs Edge computing. However, they refer to different things. Edge computing is a system that processes data near the devices and sensors that create it. Fog computing, in contrast, is a broader system that enhances edge computing by connecting more devices and sensors across a larger network.
Now, as businesses produce more raw data, relying on cloud processing and storage becomes more expensive and less efficient. This surge in data can cause delays, impacting both human resources and physical assets. Such an inefficient setup can be a hassle, wasting time and money, especially in a fast-paced global market where quick insights are key to staying competitive.
This article breaks down Fog vs edge computing in simple terms, and we compare their features in detail to help you make an informed decision.
Decoding The Basics: Edge vs Fog Computing!
What is Fog Computing?
Fog computing is a term created by Cisco. acts as a bridge between edge devices and the cloud. Fog computing relies on Edge computing since it can’t generate data by itself. It helps streamline the functions of both Edge and cloud computing by handling certain processing tasks for each.
It sits right in the middle, helping to manage the flow of data. When edge devices send a ton of data to the cloud, fog nodes step in to sift through it and figure out what really matters. They send the crucial info to the cloud for storage while either discarding the less important stuff or keeping it for later analysis. This process not only frees up cloud storage but also speeds up the transfer of essential data.
In essence, fog computing introduces a decentralized layer of computing that connects data sources with a central cloud system.
Fog Computing Types
- Client-Based Fog: Processes data in real-time using the processing capability of edge devices. Perfect for uses such as industrial IoT and driverless cars.
- Server-Based Fog: This type of fog processing and analysis depends on servers located in the fog layer. Perfect for apps that require more processing power than edge devices can offer.
- Hybrid Fog: For high processing power and real-time processing, this fog computing solution combines client-based and server-based fog computing.
What is Edge Computing?
Edge computing, as the term suggests, moves data processing closer to where it’s generated, right at the “edge” of the network. This approach can reduce or even remove the necessity for a distant data center since everything is handled locally.
Computation happens at the edge of a device’s network, which is called edge computing. This means a computer is linked to the device’s network, processing data and sending it to the cloud in real time. This computer is referred to as an “edge computer” or “edge node.”
With this technology, data is processed and sent to devices immediately. However, edge nodes send all data collected by the device, regardless of its significance.
An example of edge computing is in autonomous vehicles Like Tesla. They use edge computing devices to gather data from cameras and sensors, process it, and make quick decisions, like parking themselves. Additionally, to evaluate a patient’s condition and predict treatments, data is processed from various edge devices connected to sensors and monitors.
Fog Computing vs Edge Computing: Key Differences
Let’s get to the main part! How do the two Differ?
1. Architecture Complexity
Fog Computing Architecture
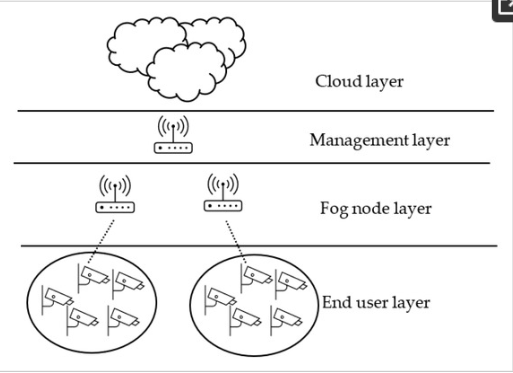
Fog computing vs Edge has three main layers: the edge layer, the fog layer, and the cloud layer. The edge layer is where data is created and gathered. The fog layer processes and analyzes this data. The cloud layer offers extra computing power and storage for the fog layer.
Edge Computing Architecture
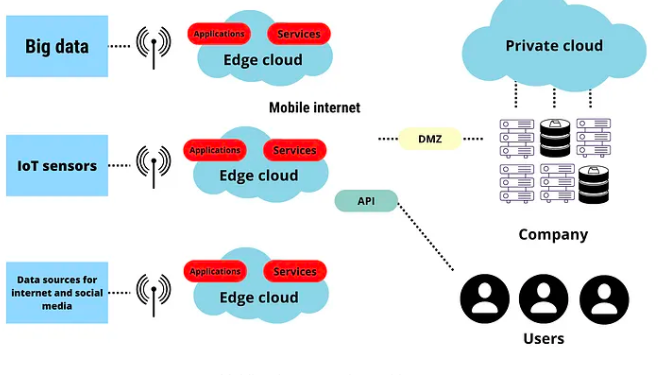
Edge computing infrastructure consists of hardware and software, including devices, networks, and other support systems. This term covers physical components such as servers, storage units, networking tools, and the software that runs on them.
Examples of Edge infrastructure include gateways, Edge AI chips, and Edge data centers. This infrastructure is essential for processing and storing data at the Edge, enabling real-time data analysis and decision-making.
2. Latency: Edge Computing vs Fog Computing
Fog Computing
This means the least amount of time needed to reply, assess, and carry out the computing request. The closeness of fog nodes to edge devices allows for quicker computing tasks and analysis replies.
Edge Computing
Edge computing, vs fog computing, however, allows for local data storage and processing, which reduces the need for cloud transfers. This results in quicker responses and a better user experience, helping to ease network congestion and cloud traffic issues.

3. Scalability
Fog Computing
Fog computing vs edge computing is highly scalable and offers extra computing resources and services to edge devices.
Edge Computing
Reducing the load on centralized servers and scalability is one of the main benefits of edge computing vs fog computing. It optimizes resource usage very efficiently by processing data locally and distributing workloads across multiple edge devices, and organizations use load balancing. IoT applications such as factory equipment or smart houses benefit greatly from edge computing. This generates a lot of data.
4. Cost Comparison: Fog vs edge computing
Fog Computing
The cost of fog computing vs edge computing involves extra expenses for hardware because it requires both Edge and cloud resources.
For non-delay-tolerant systems to be cost-effective, more hardware and software components must be included to preserve high availability and real-time processing. Devices, CPU time, network bandwidth, and code lines to speed up reaction times are a few examples. It is possible to create delay-tolerant systems according to particular requirements and available resources.
Edge Computing
Cost efficiency is a key advantage of edge computing that should not be overlooked. By processing data locally rather than relying on the cloud, businesses can lower their IT operating expenses. This approach not only cuts costs associated with cloud processing and storage but also minimizes transmission expenses by filtering out unnecessary data right at the collection point.
Fog vs Edge Computing: A Detailed Table Comparison!
The table compares both briefly.
| Fog Computing | Edge Computing | |
| Security | . The probability of data attacks is higher. | High security. Attacks on data are very low. |
| Architecture Complexity | More complicated (multiple nodes) | Simpler (device-level) |
| Data Processing Location | Close to data sources but not on the device | On the device itself |
| interoperability | High (compatible across networks) | Medium (specific to devices) |
| Maintenance | Centralized and scalable | Decentralized and specific to devices |
| Network Dependency | Moderate (needs a reliable network) | Low (can work offline) |
A key difference between Edge vs fog computing is where the computation and data analysis happen.
Fog computing vs edge computing occurs farther away from the sensors that create the data. In contrast, Edge computing happens directly on the devices linked to the sensors or on a nearby gateway device.
When using fog computing, data is analyzed within an IoT gateway. With Edge computing, the analysis happens right on the sensor or the device itself.
Essentially, Edge computing means data stays on the device, which reduces costs and allows for real-time analysis, improving performance. This also enhances security since the data remains on the original device.
In terms of capabilities, Edge computing vs fog computing can process data for business applications and send results directly to the cloud, functioning independently of fog computing.
Conversely, fog computing relies on Edge computing to generate data. It reduces the workload for both Edge and cloud computing by handling specific processing tasks.
Regarding applications, Edge computing is mainly used for less resource-intensive tasks due to the limited capabilities of devices. Examples include healthcare monitoring, predictive maintenance with sensors, and large-scale multiplayer gaming.
Fog computing, however, is suited for applications that handle large amounts of data from many devices, making it ideal for smart grids and autonomous vehicles.
In terms of storage and processing, Edge computing manages data directly within the device or very close to it. Fog computing operates differently.
Edge vs Fog Computing Similarities & Advantages They Provide!
- Increased Bandwidth: Edge and fog computing help overcome network limits that can cause overload. They lower costs and assist in managing devices and data volume in IoT settings.
- Support for Autonomous Operations: These technologies work together to process data locally, even in areas with poor connectivity, allowing data to be sent to a central platform.
- Reduced Latency and Overload: Edge and fog computing cut down latency, which is the delay in data transfer that can impact business functions. They allow for near real-time processing through local data handling.
- Enhanced Security and Privacy: These computing methods encrypt data until it leaves the edge, detecting potential cyber threats and taking preventive measures. They also secure private information.
- Adherence to Regulatory Standards: Edge and fog computing help meet regulations by processing and encrypting raw data within a specific area, ensuring data protection from global networks or secure transfer to an off-site data center.
Final Thoughts!
Fog computing vs edge computing are tech frameworks that are becoming super popular today. They both move computing power closer to where the data is generated, which helps lighten the load on centralized cloud data centers.
Edge computing focuses on processing data right at the source, while fog computing enhances this by offering extra resources and services to those edge devices. Together, these two models tackle the challenges of real-time data processing and analysis. They have tons of practical uses in our digital world today and are set to be even more crucial in the future of computing.
Not one-size-fits-all, the decision depends on your specific business needs!
FAQ’s
1. Can Fog vs Edge Computing work together?
Yes, hybrid models utilize the advantages of both methods.
2. How does 5G affect these technologies?
5G greatly decreases latency, which enhances both Fog vs Edge Computing.
3. Is Edge Computing cheaper than Fog?
Edge Computing vs fog computing is typically more affordable for real-time applications.
4. What are the main architectural differences in Fog vs Edge Computing?
Fog Computing employs a hierarchical structure with several nodes, whereas Edge Computing features a decentralized design focused on individual devices.
5. Which is more suitable for IoT applications?
Edge Computing is generally more advantageous for real-time IoT applications because it has lower latency.
6. Is a constant internet connection necessary for Fog Computing?
Yes, Fog Computing is more dependent on a reliable internet connection compared to Edge Computing.
7. How do Fog vs Edge Computing affect data privacy?
Fog provides centralized data management, enhancing oversight, while Edge minimizes risks by handling data locally.
8. Can Edge Computing function without cloud support?
Yes, Edge Computing can work independently of the cloud for certain real-time applications.



