

Incremental backups are a crucial aspect of modern data management and disaster recovery strategies. Unlike full backups, which duplicate the entire dataset every time, incremental backups are designed to capture only the changes made since the last backup, significantly reducing storage requirements and backup duration. This process works by identifying and saving newly created, modified, or deleted files, ensuring that only the most recent data alterations are preserved. By incorporating incremental backups into their backup routines, organizations can streamline the backup process, conserve storage space, and minimize backup windows.
How do incremental backups work?
Incremental backups operate on the principle of capturing and backing up only the changes made to data since the last backup. When the initial full backup is performed, it creates a complete copy of all data. Subsequent incremental backups then identify and record only the files or portions that have been newly created, modified, or deleted since the last backup.
This approach drastically reduces the backup size and time, as it focuses solely on the altered data, rather than duplicating the entire dataset each time. To ensure data consistency and integrity, incremental backups rely on timestamps and archive bit flags to identify the files that require backup.
When restoring data, the backup software combines the last full backup with all the subsequent incremental backups to reconstruct the most up-to-date version of the data. This efficiency makes incremental backups an invaluable tool in optimizing storage usage, shortening backup windows, and simplifying the restoration process in the event of data loss or system failures.
Types of Incremental Backups
Within the realm of data backup and recovery, incremental backups offer distinct categories that cater to various organizational needs. Let’s delve into the primary categories of incremental backups:
Traditional Incremental Backup
As previously mentioned, traditional incremental backups capture only the data that has changed since the last backup, whether it was a full backup or a previous incremental backup. This approach results in smaller backup sizes and faster backup operations, but it may require multiple backup sets during the restoration process.
Differential Incremental Backup
Differential incremental backups capture all the data that has changed since the last full backup, regardless of the number of incremental backups taken in between. Each subsequent differential backup grows in size, as it accumulates all the changes since the last full backup. During restoration, only the last full backup and the latest differential backup are needed, simplifying the process compared to traditional incremental backups.
Incremental-Forever Backup
This method continuously creates incremental backups without relying on a full backup as a starting point. It builds on the last successful backup, be it a full or incremental backup, and captures only the changes made since that specific point in time. Incremental-forever backups combine the efficiency of incremental backups with the advantage of not needing periodic full backups.
Synthetic Full Backup
Synthetic full backups create a synthesized full backup by combining a previous full backup with subsequent incremental backups. Rather than performing a new full backup, the backup software constructs a full backup “synthetically” using the data from previous backups. This process reduces the impact on production systems and backup windows while still providing the benefits of a full backup during data restoration.
Incremental Reverse Backup
This method is less common but worth mentioning. Incremental reverse backups start with a current full backup and then capture changes in reverse order, effectively working backward in time. This approach may be useful in certain scenarios where a particular state of data from the past is required.
The choice of incremental backup type depends on factors such as data volume, storage capacity, recovery objectives, backup frequency, and the organization’s specific backup requirements. Each type has its strengths and limitations, and the most suitable approach will vary based on the unique needs and resources of the organization.
Incremental vs Differential Backup
Incremental Backup and Differential Backup are two widely used backup strategies to safeguard data and facilitate recovery. With Incremental Backup, only the data that has changed or been added since the last backup is backed up, resulting in a more space-efficient and quicker backup process. However, during restoration, all backups since the last full backup are required, potentially making the recovery process slower. On the other hand, Differential Backup captures all changes since the last full backup, making restoration faster as only the latest full backup and the most recent differential backup are needed. Nonetheless, this method demands more storage space due to storing all changes since the last full backup.
When deciding between the two, organizations consider factors such as backup frequency, available storage capacity, and recovery speed requirements. Often, a blend of both strategies is adopted to strike an optimal balance in their backup approach.
Benefits of Incremental Backup
Incremental backups offer several significant benefits, making them a valuable choice for data backup and recovery strategies:
- Efficient Use of Storage: Incremental backups only store the changes made since the last backup, whether it was a full backup or a previous incremental backup. This approach results in smaller backup sizes compared to full backups, optimizing storage utilization and reducing the need for extensive storage resources.
- Faster Backup Process: With incremental backups, only the modified or new data is captured, making the backup process quicker and more efficient. This reduced data volume significantly shortens the backup window, minimizing the impact on system performance and network resources.
- Reduced Bandwidth Consumption: Incremental backups transmit and store less data than full backups, resulting in lower bandwidth usage. This benefit is particularly advantageous for remote or cloud-based backup solutions where limited network resources are a consideration.
- Increased Data Protection: Since incremental backups are taken more frequently, there is a reduced risk of data loss in case of system failures, disasters, or cyber threats. The frequent backups ensure that changes are captured promptly, minimizing the potential for data loss between backup intervals.
- Versioning and Point-in-Time Recovery: Incremental backups facilitate versioning and point-in-time recovery, allowing users to access multiple historical versions of their data. This capability is valuable for tracking changes over time and recovering data from specific points in history.
Drawbacks of Incremental Backup
While incremental backups offer numerous benefits, they also come with some drawbacks that organizations should consider when choosing their backup strategy:
- Increased Complexity: Managing incremental backups requires careful planning and tracking of backup sets. As each incremental backup builds upon the previous one, the restoration process may become more complex, especially if multiple incremental backups are involved. This complexity can lead to longer recovery times and potentially introduce errors during the restoration process.
- Dependence on Previous Backups: Incremental backups rely on the existence and integrity of previous backups, especially the last full backup. If any of the previous backups are corrupt or missing, it could impact the ability to restore data correctly. Organizations must ensure the regular verification and integrity of all backup sets.
- Longer Restoration Times: While incremental backups offer faster backup times, the restoration process may take longer, especially when recovering data from multiple incremental backups. In cases where a significant number of incremental backups are involved, the time taken to restore data can become a concern.
- Greater Risk of Data Loss: Since incremental backups rely on capturing changes from the last backup, any unnoticed data corruption or errors during previous backups could propagate through subsequent incremental backups. This could lead to a situation where corrupted data is backed up multiple times, increasing the risk of data loss.
- Increased Backup Media Requirements: In scenarios where organizations retain multiple incremental backups, the number of backup media needed for long-term retention can grow significantly. This can lead to additional costs and storage challenges for organizations with strict data retention policies.
How to Create and Restore Incremental Backups
In the preceding guide, you will acquire knowledge on how to create an incremental backup using the “tar” command. Additionally, you will learn how to carry out the restoration operation using the same “tar” command.

Generate Data Files
To facilitate this tutorial’s objectives, we’ll generate specific files for conducting the incremental backup.
To start, employ the following command to establish a data directory:
mkdir -p /backup/data
Subsequently, generate several files using the following command:
cd /backup/data cat /etc/sysctl.conf > test1.txt cat /etc/sysctl.conf > test2.txt cat /etc/sysctl.conf > test3.txt cat /etc/sysctl.conf > test4.txt cat /etc/sysctl.conf > test5.txt cat /etc/sysctl.conf > test6.txt

Initiate the Level 0 incremental backup
Execute the provided command to carry out the incremental backup.
cd /backup tar --verbose --verbose --create --gzip --listed-incremental=/backup/data.sngz --file=/backup/data.tgz dataUpon running the above command below output will be obtained.

At this point, utilize the following command to display the contents of the incremental backup data from the “data.tgz” file.
tar --list --incremental --verbose --verbose --file /backup/data.tgz

Initialize the Level 1 incremental backup
Within this segment, our objective is to generate a level 1 incremental backup. To accomplish this, we’ll utilize the “data.sngz” snapshot file, which will enable us to create a fresh backup archive file named “data1.tgz.”
rm -rf /backup/data/test2.txt cat /etc/sysctl.conf > /backup/data/test7.txt
Execute the provided command to carry out the incremental backup.
cd /backup tar --verbose --verbose --create --gzip --listed- incremental=/backup/data.sngz --file=/backup/data1.tgz data

As observed, the aforementioned command will solely back up the most recent changes made subsequent to taking the level 0 backup.
Run the below command.
tar --list --incremental --verbose --verbose --file /backup/data1.tgz

The letter “Y” denotes the presence of a file in the archive.
Perform the restoration of the backup using Tar Incremental Backup
First, delete the data directory with the following command to perform restoration operations.
rm -rf /backup/data
Run the following command to restore the data directory, begin by extracting the data directory from the level 0 backup. Since the level 0 backup serves as the foundation of the data directory, this step is essential.
cd /backup tar --extract --listed-incremental=/dev/null --file data.tgz
To check the restored files run the below command:
ls -l data

Now, proceed to extract the data from the level 1 incremental backup using the provided command:
cd /backup tar --extract --listed-incremental=/dev/null --file data1.tgz
Verify the data directory by executing the following command.
ls -l data

The above output will be obtained.
How Incremental Backups are Implemented in CyberPanel?
Incremental backups are carried out by solely backing up the data that has undergone changes or updates since the previous backup, rather than duplicating the entire dataset during each backup iteration. This method enhances efficiency, leading to reduced storage usage and backup time.
CyberPanel now incorporates Backup V2, a feature that enables incremental backups. This article offers a detailed, step-by-step guide on implementing Backup V2 in CyberPanel. With Backup V2, users can set up SFTP backup and Google Drive backup. Below, we’ll walk you through the process of achieving this functionality.
Introducing CyberPanel Backup V2
Login to your CyberPanel dashboard.
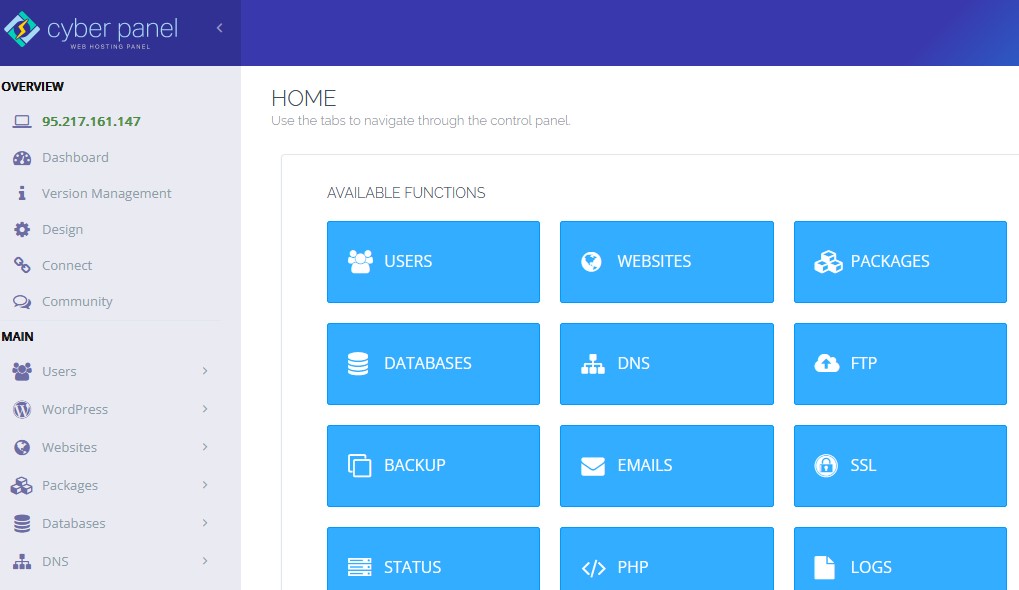
You will see a menu on your left sidebar after upgrading your CyberPanel to V 2.3.4 and the first thing that you need to configure the backends.
Then select the website and backup type for which you want to configure this backend.

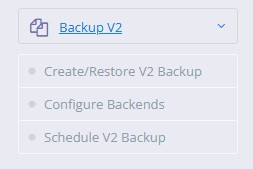
Set up your account by entering your account name.
Now you will be redirected to our platform where you have to log in with your email and password.

You don’t need to do anything on the platform site, this is just required to authorize the app with Google Drive. Then it will ask you for google drive access, you just need to approve that and you are good to go.
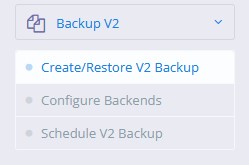
Once the backend is configured, click on Create/Restore V2 Backup.
Now scroll down a little and select website, repository, and backup content. If you select the data then only the file in the file manager will be backed up. If you select all of the three options then everything will be backed up. Upon clicking create backup a backup will e created.
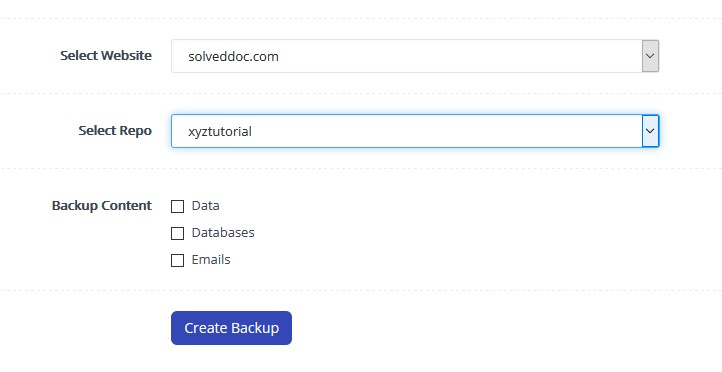
The above method is a manual way of creating a backup. If you want to restore the backups click Restore backups.
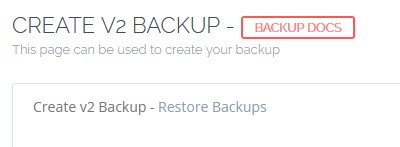
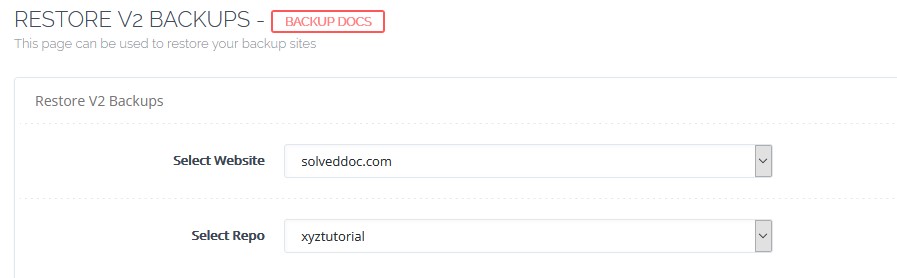
Select the website for which you want to restore the backup. Select the repository and you will see a list of snapshots that you can restore.
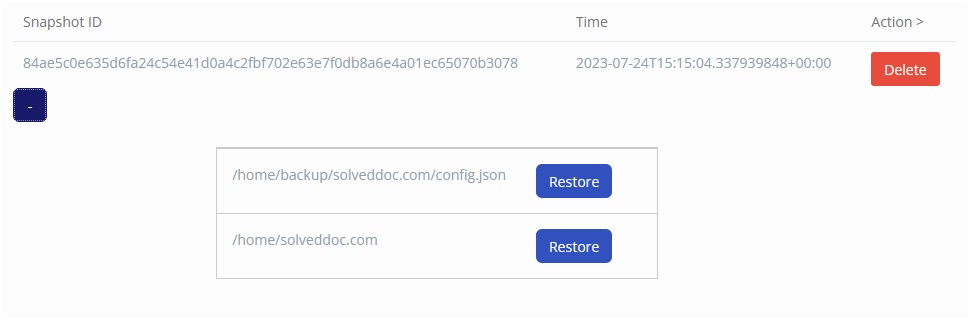
Here you can see the backup of data. You can restore individual databases of your website as well. If you click restore then the database will get restored. With each backup, there is a configuration file. It is a config file in which CyberPanel stores all the metadata.
The next step is scheduling the back up which is the most important.
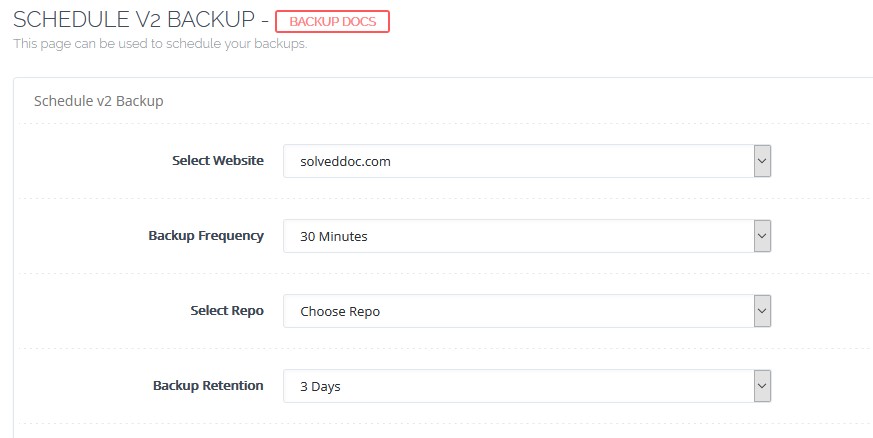
To create a backup schedule, follow these steps:
Choose the website or data you wish to back up. Set the backup frequency. Define the backup repository or storage location. Determine the backup retention period (number of days to retain backups). Select the content you want to include in the backup. Click “Create Schedule” to finalize the setup. The system will then generate a backup schedule based on your preferences. Backups older than the specified retention period will be automatically deleted.
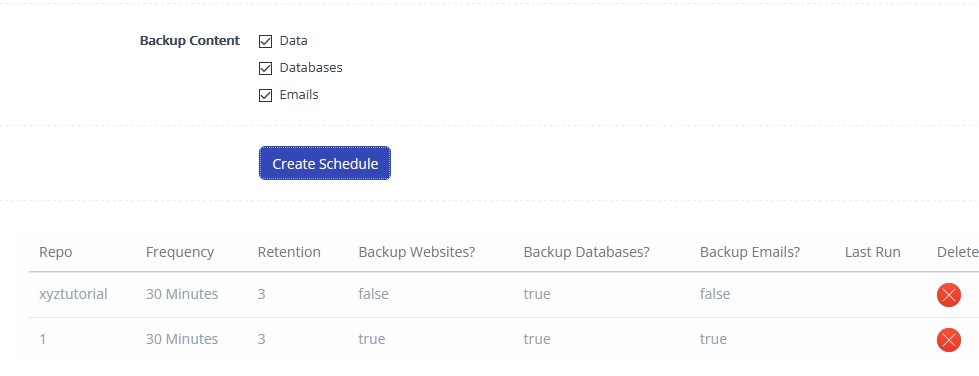
This is how you can utilize Backups V2, which are highly resilient, built with a sturdy backend, offer incremental backups, and ensure fast performance.
If you want to configure the backend from CLI (without google drive or SFTP), go to List Websites from the Websites section.
Click on Manage.

Click on vHost Conf.
Click on SETUP SSH/SFTP ACCESS.
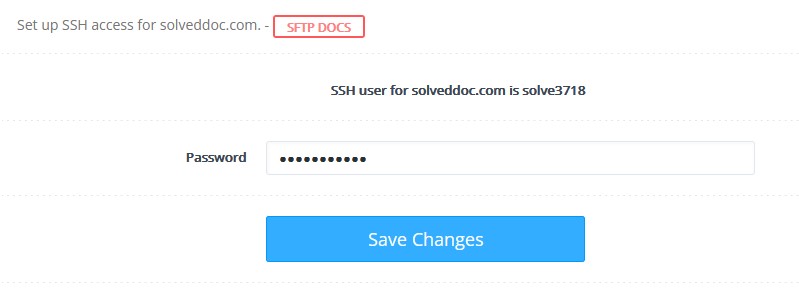
Set up SSH access by setting a Password and clicking on save changes.
Now you just have to log in to your terminal and run the command:rclone config
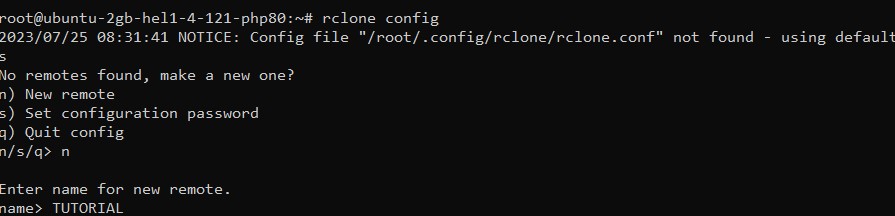
Here you can configure a new remote, set config password, or quit config. So let’s say you want to create a new remote you will enter n and you can enter the new remote CLI then here you have a list of all the backends supported by Rclone.
Once you have configured a backend from here you don’t need to do anything else you can read up Rclone documentation on how to configure a backend from CLI. Once that is done, you will be able to see that Repository in Create/Restore V2 Backup and in the Schedule V2 Backup section as well.
FAQs
What are the benefits of using incremental backups in data management and disaster recovery strategies?
Incremental backups offer several advantages, such as efficient storage usage, faster backup processes, reduced bandwidth consumption, increased data protection, and support for versioning and point-in-time recovery. Organizations can optimize their backup routines, conserve resources, and minimize downtime in case of data loss or system failures by incorporating incremental backups.
What are the drawbacks of implementing incremental backups, and how can organizations address these challenges?
While incremental backups provide numerous benefits, they also come with certain drawbacks. These include increased complexity during restoration, dependence on previous backups, longer restoration times in certain cases, greater risk of data loss due to unnoticed errors in previous backups, and increased backup media requirements for long-term retention. Organizations can mitigate these challenges through meticulous planning, regular verification of backup sets, and a balanced backup approach.
What are the essential factors to consider when implementing incremental backups in a data management strategy?
Organizations should carefully consider several factors when incorporating incremental backups into their data management strategies. These factors include data volume, available storage capacity, backup frequency, retention periods, network resources, and the specific backup requirements of the organization. A well-balanced approach will ensure an efficient and effective backup routine.
How frequently should incremental backups be performed?
The frequency of incremental backups is a critical aspect of an organization’s data backup and recovery strategy. It revolves around two essential factors:
1. The rate of change in the data
2. The acceptable data loss window in the event of a failure
Determining the optimal frequency of incremental backups is essential to strike the right balance between data protection and resource utilization.
Ultimately, the frequency of incremental backups should be a well-informed decision based on the organization’s unique data characteristics, business requirements, and risk tolerance. Striking the right balance ensures that data loss is minimized, data integrity is maintained, and the organization is prepared to recover quickly and effectively in case of a data disaster. Many organizations perform incremental backups daily or multiple times a day for critical data.
