

“What is Hadoop” is a common question in today’s world. Big data processing has developed based on the need to store and analyze very large volumes of information in today’s information world. Very widely used is Apache Hadoop, as a framework for handling big data. The Hadoop system has changed how data is handled within organizations today, in that the type of scalability and fault-tolerant system offered by it enables even an independent company to extract insight from complicated datasets.
In short, Hadoop is the underlying base that enables data warehouses, analyzes social media interactions, and powers recommendation engines, amongst many others. This post looks into what Hadoop is, its core constituents, how it can be integrated with Apache Spark, the related software ecosystem, practical use cases, and even how CyberPanel can support Hadoop deployments. The tool for those individuals who are going to navigate the big data landscape, Hadoop will reveal new possibilities for data and analytics management.
What is Hadoop?
Core Concept and Evolution of Hadoop
To understand What is Hadoop, it’s important to look at its development as an open-source framework
It was developed under the Apache Software Foundation as an open-source framework for storing big data across clusters of computers. The inception dates back to the papers on Google’s MapReduce and Google File System (GFS). These were the building blocks in the architecture of Hadoop. By dividing large amounts of data into manageable pieces and then processing it all at once, across multiple machines, it does big data processing while remaining efficient and resilient.
Another sign of Hadoop’s ongoing relevance is the growing demand for skilled professionals. Platforms like Hadoop-Jobs offer a space where companies can find qualified data engineers and analysts. Whether it’s in finance, healthcare, or media, employers are actively seeking Hadoop talent to support their big data infrastructure and projects.
Core components of Hadoop
To answer What is Hadoop, it’s essential to explore its core components: Hadoop has four main modules, each for doing a different function in the ecosystem:
Hadoop Distributed File System (HDFS): HDFS is the storage layer of Hadoop. It allows storing data on a cluster of machines. Data is divided into blocks, replicated, and distributed across several nodes for high availability. The fault-tolerant system ensures data access even when some nodes fail.
MapReduce: MapReduce is a kind of programming model that processes large datasets in parallel form, in a Hadoop cluster by breaking up tasks into smaller sub-tasks, calculating them, and then collecting the results of calculations, hence making it possible to process data faster and more efficiently.
YARN (Yet Another Resource Negotiator): It oversees the cluster resources and maps tasks. It makes Hadoop helpful for multiple applications. It provides a flexible framework where applications can run independently on a Hadoop cluster. Thus, it is scalable and adaptable.
Hadoop Common: It provides utilities and libraries that support other Hadoop components. It includes the required Java Archive or JAR files and scripts that start the Hadoop.
Benefits of Using Hadoop
Scalability: Hadoop can grow from a single server to thousands of machines, using local computation and storage.
Cost-Effectiveness: As an open-source framework, Hadoop saves companies from the cost of proprietary hardware and software.
Flexibility: Hadoop can process both structured and unstructured data, which is of importance to most modern applications involving the handling of data.
What is Hadoop Used For?
Hadoop has emerged as a new doorway to big data solutions across various types of industries, powering complicated data applications that require storage, processing, and analysis of large volumes of information. Here are some primary applications of Hadoop in different fields:
Business Intelligence: This further enables the organization to store huge data warehouses and do in-depth analytics on them using Hadoop. Companies can analyze historical data to get insights into customer behavior and market trends and understand business operations using Hadoop. Then, tools like Apache Hive and Impala allow users to query the data using SQL-like syntax, making it very easy to do data analysis.
Social Media and Sentiment Analysis: It includes a high volume of unstructured data from social media sites such as Twitter, Facebook, and LinkedIn. Hadoop allows these sites to digest and analyze the interaction of users, content, and preferences, which further supports targeted advertising and personalized recommendations.

Risk Management: It has financial institutions using Hadoop to analyze transaction data to uncover patterns that may indicate fraudulent activity. With Hadoop processing data in real-time, banks are able to identify, sense, and thereby prevent fraud more effectively.
Healthcare and Genomics: Healthcare organizations are finding a good application for Hadoop to store and process patient records, medical images, and genomic data. It is used for data-intensive applications in the area of genome sequencing, enabling the early diagnosis and treatment of diseases.
Search Engine and Recommendation Systems: Yahoo, eBay, and Netflix use Hadoop to drive search engines and recommendation engines. These systems can recommend lots of useful content and products to end-users by analyzing the behavior and preferences of users.
Telecommunication and Network monitoring: Hadoop is applied in the telecom sector for the processing of network data. This ensures efficient service and customer satisfaction. It enables network service providers to track problems before they eventually reach the customers, thanks to the ability to execute the process in real-time.
These applications undoubtedly demonstrate how Hadoop can be made to function in a broad range of industries, thus representing an adaptable and scalable aspect of data management and processing. Organizations looking to leverage these capabilities often choose to hire Hadoop developers to build efficient, industry-specific big data solutions.
What is Hadoop Software?
Hadoop software integrates several tools and components into a complete data management solution. Here are some basic Hadoop-related software programs:
1. Apache Hive

Apache Hive is a data warehousing solution that enables users to pose queries over big datasets in Hadoop using SQL-like syntax. The system translates SQL-like queries into MapReduce tasks, so users familiar with SQL can work quite efficiently over Hadoop. Hive supports summarization of data, ad-hoc queries, and large-scale analysis, and it is thus apt for business intelligence applications.
Use Case:
Hive is widely used by data analysts and business intelligence teams who want to process structured data without the need to write complex MapReduce code. For instance, an e-commerce company may use Hive while analyzing customer purchase data; it can then track trends and predict what is likely to happen based on historical data.
2. Apache Pig
Apache Pig is a high-level scripting platform that allows people to process big datasets in Hadoop. Through its scripting language, Pig Latin, it allows the user to perform extensive data transformations and analysis capabilities. The Pig scripts get converted into MapReduce jobs, making data processing more accessible and easy.
Use Case:
Pig is widely adopted for ETL operations. For example, as it cleans, filters, and transforms unstructured data, social media sites may employ Pig to dig further to get an insight into the engagement behavior of users.
3. Apache HBase
HBase is a NoSQL database, allowing real-time read and write access to data in Hadoop. Highly scalable, structured, and semi-structured data sets make it especially suitable. HBase specifically applies to applications requiring real-time access to the data and analytics.
Use Case:
Companies that require accessing humongous quantities of data in the shortest span use HBase. For instance, e-commerce sites would use HBase for receiving inventory information and tracking their orders in real-time even under heavy load.
4. Apache Sqoop
Sqoop is a transfer tool that enables one to transfer data between Hadoop and relational databases like MySQL, and PostgreSQL. It can import as well as export data efficiently which is a must for integration of data coming from various sources.
Use Case:
It is a tool for transferring data from the Hadoop environment to traditional databases. Companies that store data in hybrid environments use Sqoop to transfer their data between Hadoop and traditional databases. For example, an organization can utilize Sqoop to upload historical data about transactions from relational databases into Hadoop to be processed and analyzed in batches.
5. Apache Flume

Flume is a data ingestion tool that can be used for the efficient collection and moving of large amounts of log data into Hadoop. It can be quite useful in ingesting streaming data from any server logs into HDFS for further analysis.
Use Case:
Flume is highly used by web companies in the analysis of log data in servers. For example, a media streaming company might use Flume for capturing and analyzing the real-time log data from their servers for understanding usage trends and troubleshooting service problems.
6. Apache Zookeeper
Zookeeper is a coordination tool for distributed applications in the Hadoop ecosystem. It coordinates configuration information, naming, synchronization, and group services to ensure that nodes in a Hadoop cluster are aware of each other’s states.
Use Case
Zookeeper is used to manage and maintain the configuration of distributed applications ensuring consistency and reliability. Hadoop’s YARN and HBase both depend on Zookeeper for task coordination and node monitoring.
7. Apache Oozie
Hadoop job workflow scheduler Oozie ensures automated and sequential execution of MapReduce, Pig, Hive, or Sqoop jobs according to workflows or coordinated jobs.
Use Case:
Companies performing complex data processing on Hadoop rely on Oozie to schedule and manage multi-step workflows. For instance, a data science team could use Oozie to schedule a daily running ETL pipeline that will take some time to process and prepare the data in anticipation of analysis.
8. Apache Mahout

Mahout is a library for machine learning; therefore, Hadoop users can build scalable machine learning applications using Mahout: recommendation engine, clustering, and classification. Mahout makes full use of Hadoop’s large-scale distributed computation abilities in training and applying machine learning models in really large datasets.
Use Case: Mahout is employed throughout e-commerce websites to implement recommendation systems. By filtering purchase histories and customer preferences, Mahout can suggest products for customers based on their past behaviors and interests.
These make Hadoop truly a comprehensive solution for all aspects of dealing with big data, from ingestion to transformations and up to real-time access and advanced analytics.
What is Hadoop Spark?
Apache Spark is that open-source engine designed to be used for big data processing, known to have speed and flexibility. In using Hadoop, Spark is mostly taken into advantage to improve performance especially if data needs iterations to achieve computation.
Unlike MapReduce, Spark processes data in memory, making it up to 100 times faster for certain tasks.
Word Count in Hadoop with Spark
Here is an easy word count example in Spark. We will be using the PySpark library-Python API for Spark to count words in a text file.

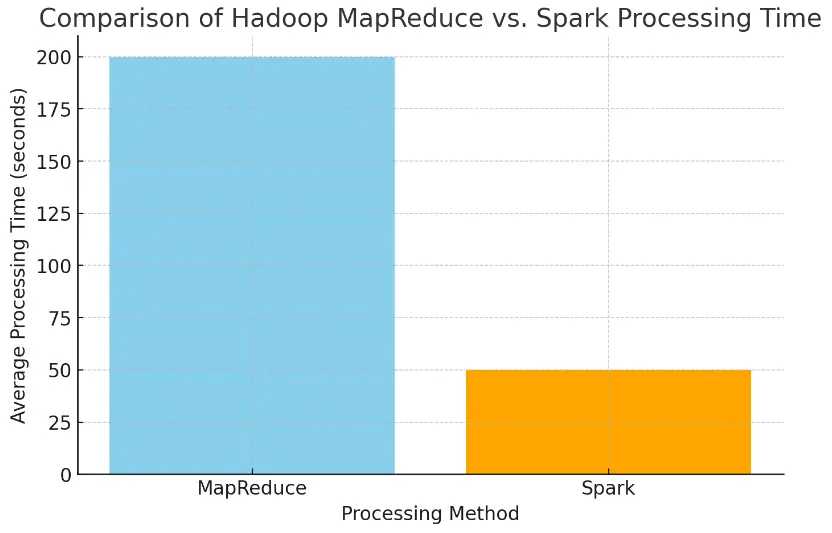
A Graphical Comparison of The Performance
To elucidate the performance benefit of Spark over traditional Hadoop MapReduce, I’m going to add an example graph showing a comparison of the average processing times of each for an iterative data processing task.
Example Graph: Processing Times for Iterative Task (Hadoop MapReduce vs. Spark)
Processing times over the same data processing task using Spark and MapReduce, are given below. The example quite clearly shows the significant cut in time offered by Spark due to its in-memory processing.
What is Hadoop Alongwith CyberPanel
CyberPanel is a powerful web hosting control panel. It simplifies the jobs of managing Hadoop environments. And here’s where CyberPanel could complement Hadoop deployments:
Efficient Resource Allocation: This control panel feature would enable a lightweight manager to efficiently tune server resources, with high-performance distributed nodes being the largest criteria in Hadoop.
Backup: It has reliable backup and restoration options to ensure data redundancy and recovery in the event of node failure.
Security Features: Its built-in security measures include firewalls and SSL certificates that prevent unauthorized access and cyber attacks on the Hadoop environment.
Resource Monitoring: CyberPanel also actively monitors server resources, making it easier for administrators to manage Hadoop clusters rated high on reliability and performance.
FAQs on “What Is Hadoop”
1. What is Hadoop and why is it famous?
Hadoop is an open-source framework for processing as well as storing large amounts of datasets. It gains popularity from its scalability and cost-effectiveness along with fault tolerance.
2. What is Hadoop use?
Hadoop is used by finance and healthcare industries for analytics as well as by telecommunication industries for fraud detection or personalized recommendations.
3. How does Hadoop differ from Spark?
Hadoop uses a MapReduce framework that takes time to process its data, while Spark in-memory takes less time for the processes.
4. What are the major components of Hadoop?
HDFS, MapReduce, YARN, and Hadoop Common.
5. Is Hadoop free to use?
Yes, Hadoop is open-source and free to use.
6. How does Hadoop manage large datasets?
Hadoop splits huge data into blocks that reside in various clusters. High availability and parallel processing of a process are ensured.
Conclusion: Redefine Your Future with Big Data and Hadoop
To sum up, understanding what is Hadoop is essential to unlocking big data potential. Hadoop, as the core of data-driven society today, extends beyond just a framework, but the backbone of the transformed insights across different industries. Be it the core elements, such as HDFS, MapReduce, YARN, or the broader Hadoop, it finally integrates modern tools like Spark in an organization to oversee and process copious amounts of datasets in real-time to help decision-making and customer insights through innovative solutions.
With CyberPanel, Hadoop finds an extension of its powers since it makes effortless management along with security enhancements and also optimizes resource allocation. This way, be it business intelligence better detection of fraud, or fetching insights through social media analytics, Hadoop opens all the new doors of impactful data applications.
Get ready to discover the full potential of big data. Begin your Hadoop journey today and unlock smarter data processing, analysis, and application in the future!
Do you need further explanation? We have a video for you on “What is Hadoop”!

